Facebook marketplace seems like the perfect place to grab a bargain on preloved bicycles looking for a new home. But is that new bicycle stolen property? Facebook’s lack of regulation, enforcement and inherent design makes it the perfect platform for stolen goods. Combine that with police unwillingness to aid in bike theft recovery (when compared to automobiles), it’s very common to see stolen bicycles on Facebook Marketplace.
Before we go to far, the below checks aren’t perfect. They are signals to be cautious but not definitive proof that a good was stolen or not.
Additionally the person selling the item might not even be aware it was stolen. They might have purchased it from someone else, it might have acquired from a police auction, it could be from an estate sale, or some other legitimate means.
Finally, we also need to consider why bikes get stolen. With the increased cost of living, housing crisis and lack of social support - people are going to resort to any means to get by. This isn’t excusing their actions, but provides context as to why we might be in this position start with.
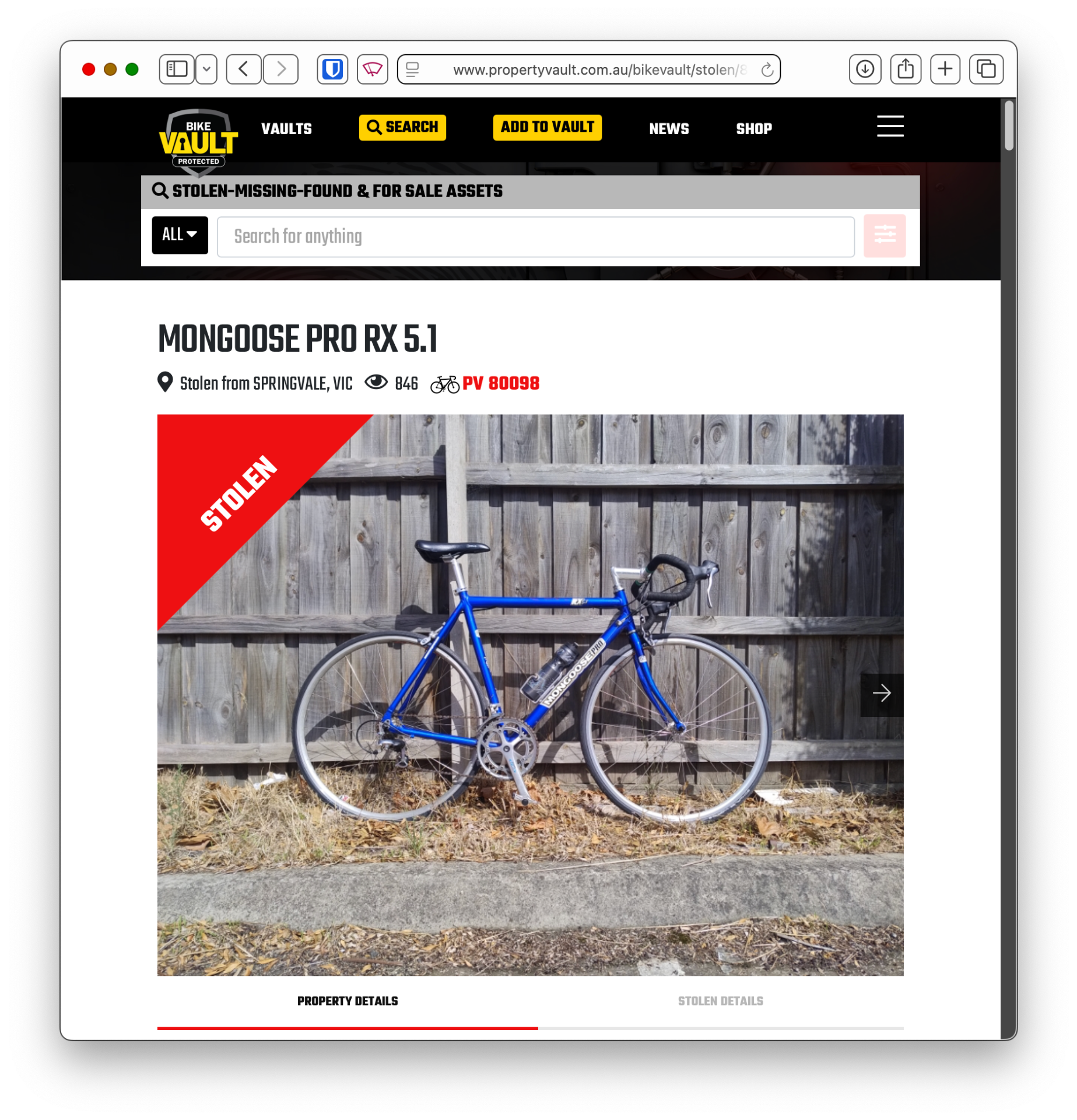
PropertyVault
First up - the obvious. Has the bicycle been listed on a stolen bicycle websites. In Australia the goto is PropertyVault. If you do find out that the bicycle you’re interested in is listed on PropertyVault then please fill out the contact form on the site. Take screenshots of the Facebook listing in case it is removed.
Dodgy spray paint
For low end bikes, it’s not uncommon for bicycles to be spray painted to remove all discernible markings and customisation. The thought process I think here is that they can sell it has a generic bicycle without being caught or detected from selling “your” bike. I’m really not sure who buys these - but highly likely to be stolen. Often you see overspray on cranks, chain, spokes because disassembly isn’t trivial and who has time for that.
Selling a lot of bikes
The average person doesn’t have a stockpile of 20 bikes they are trying to sell. There’s certainly people who do like bikes, like repairing and enjoy selling them to get people riding so you do need to use some judgement here. Some ways of determining legitimacy further: are they operating under a company? Do they seem to have a workshop? Do the descriptions seem like they are written by someone who knows/likes bikes?
It’s also worth looking at sold history. Even though a seller might only have 3 bikes up for sale, they might have sold many many more under the same profile.
Broken spokes / damage from lock
This is more common on bikes with Axa locks, but check for spokes being damaged. It’s very easy for spokes to be damaged when snapping locks through twisting or in the case of Axa, not realising its locked and trying to ride. There might also be evidence of where an Axa lock used to be mounted.
Missing e-bike charger
There are many e-bike charger standards and pretty much all e-bikes come with a charger. If the bike is being sold without the charger, or without the key to remove the battery, then good chance its been stolen off the street. The common story is “lost in house move” - which to be fair, is very likely. But treat with a lot of suspicion.
Selling lots of high value items
Is the seller also selling other suspicious items. Lots of powertools? Many iPads and iPhones? Gold and jewellery?
Profile doesn’t match actual person / sus
Facebook profiles that don’t match the sellers location or the person you meet doesn’t look like the profile picture. Maybe it’s a brand new profile, or no other items listed.
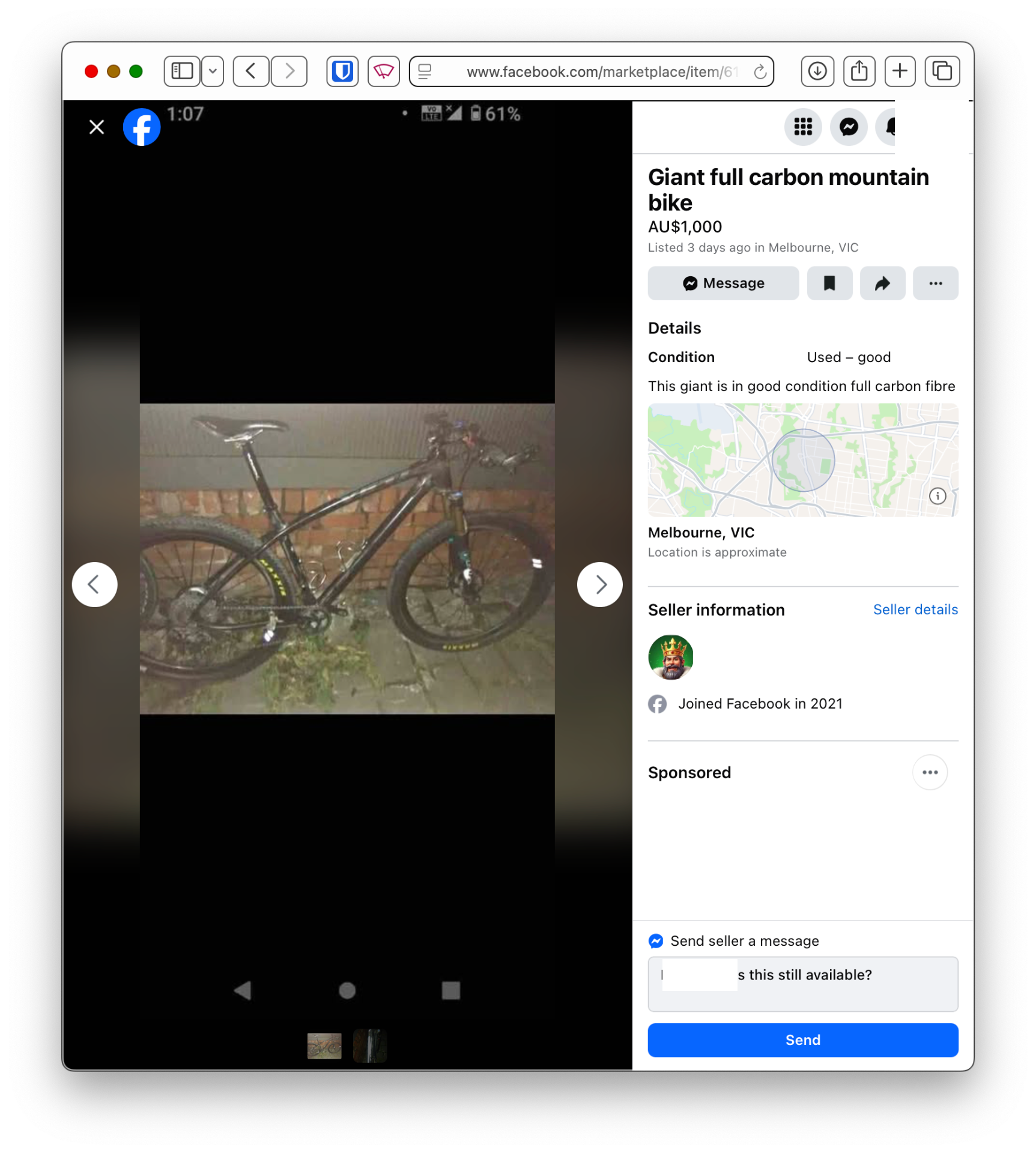
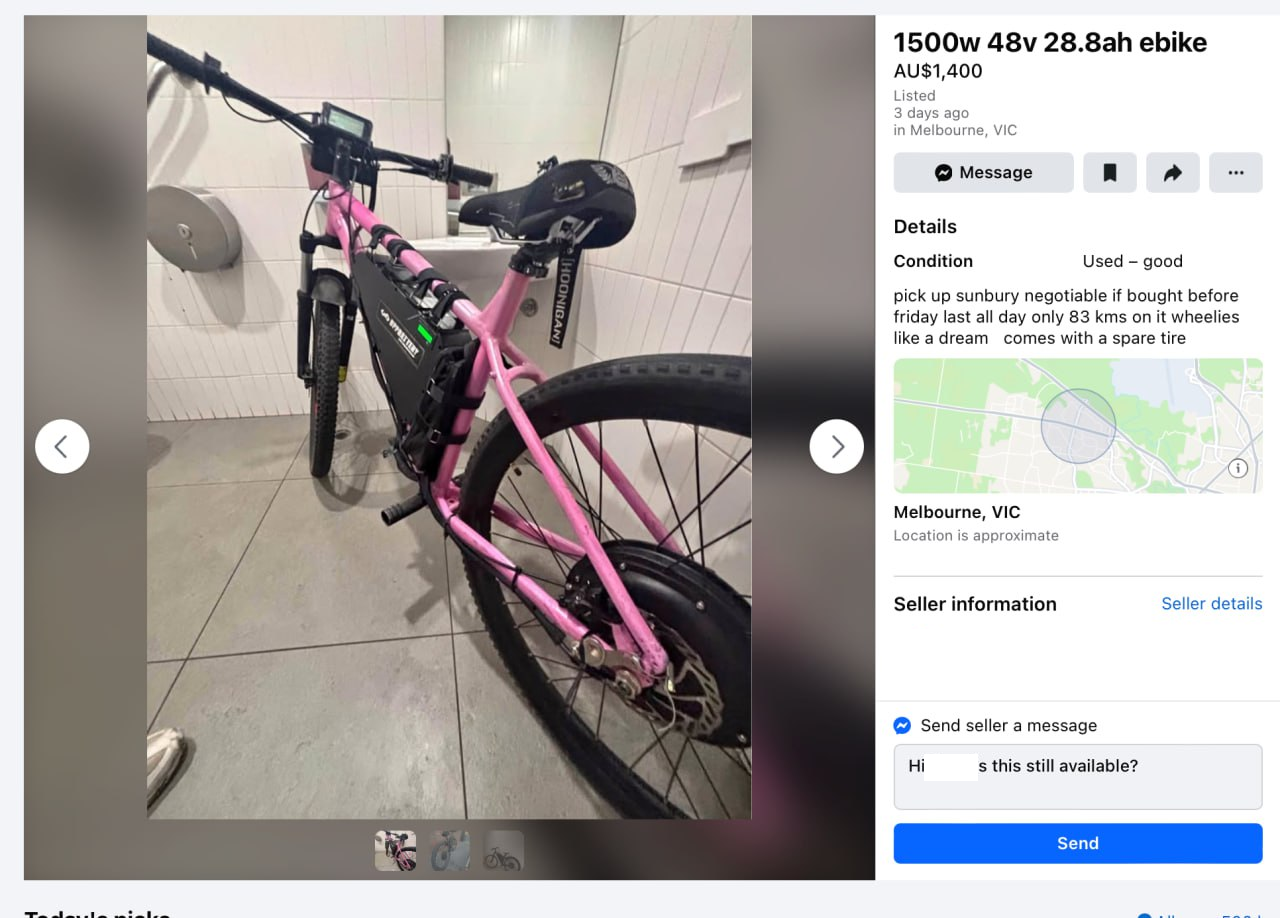
Poor / odd photos
High end bikes being sold with 2 crappy at night photos? Photo taken from within a public toilet? (I’m not even joking)
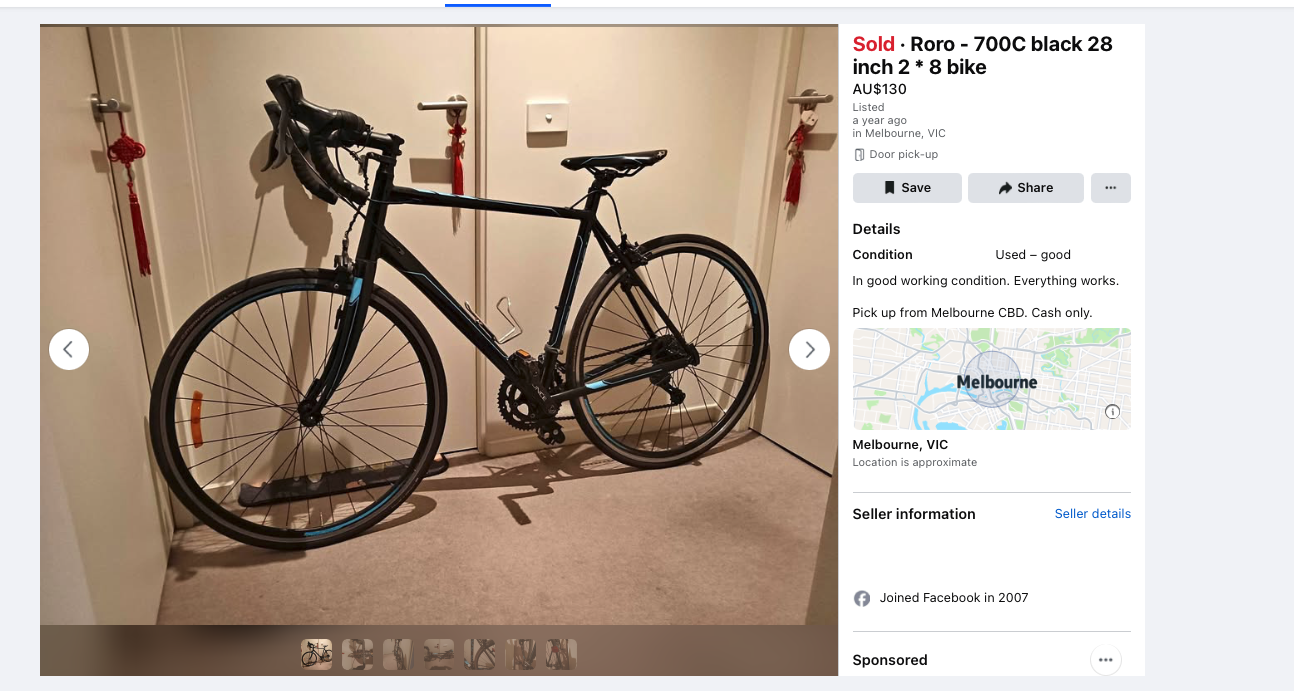
Incorrect model or part descriptions
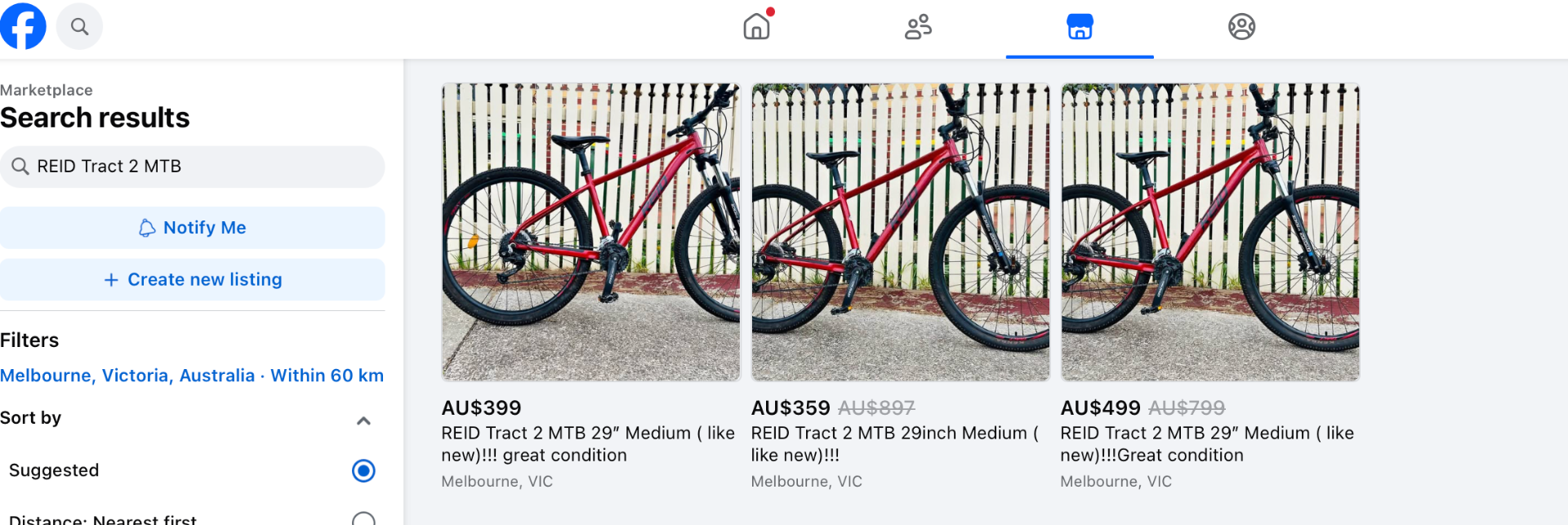
Not looking for typos here but rather completely getting the model or parts wrong. In the below example this Aldi “ROAD 700” is being sold as a “RORO” because thats what it looks like when you look at the decal from the side. Another common example is when parts have been replaced. Sellers sometimes use the specifications found on manufactures websites rather than the actual parts installed. Some listings even have have bikes model or brand listed as one of the drivetrain parts like “Shimano”.
Example of parts not matching bike:
Same bike listed by multiple sellers
Some sus sellers use multiple accounts to sell their wares. Sometimes they get sloppy and sell the same product on multiple accounts.
If you’re reading this looking for possible solutions to Toyota LandCruiser 200 series 4WD system or door locks - remember that this post is very bias’d towards a very specific problem. If you have a sun roof then check electrical connectors and wiring for corrosion and water damage first. If your actuator isn’t working correctly start by cleaning it.
It’s unlikely that your issue will be the same as ours.
While/after visiting Adelaide for Horus 64B launch our car had developed two issues. The 4HI/4LO actuator was failing to operate correctly - the main symptom was clicking/ticking.
The second was slow door locking action. Lets tackle this one first. For Horus 64B launch I decided to locate the door motor wire for a passenger door and disconnected it. The reason for this is that it allowed us to safely run cables out the window without the risk of coax cables being pulled out from accidental door opening.
After the launch I wired the door back in but the doors unlocked really slowly and often the passenger door I modified failed to operate at all. I checked all the fuses, voltages, terminals and everything seemed fine. Disconnecting the motor and the other doors look worked ok, though maybe a little slower than I was used to. Maybe it was a coincidence? I’ve ordered a replacement door motor to see if that resolves the issue. We’ll return to this some other time.
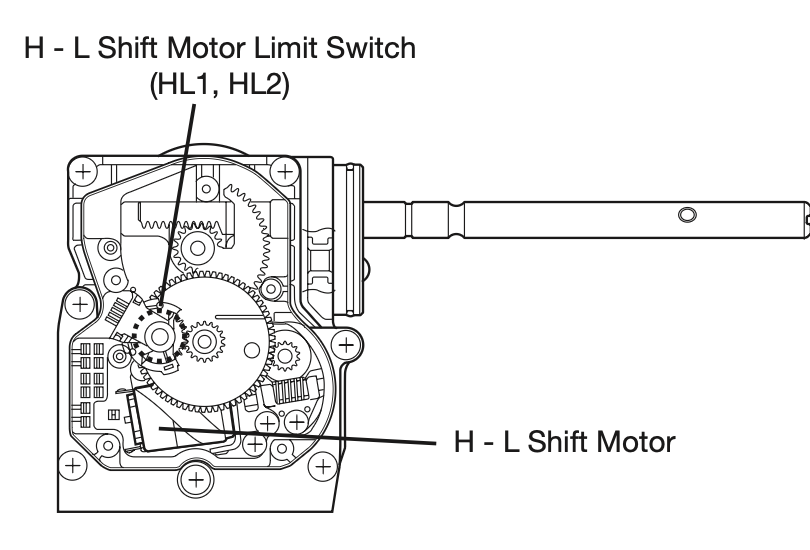
Back to the 4LO problem. The issue was first discovered when performing a routine exercise of the actuator. This happens so that the unit’s grease doesn’t dry up and cause issues with the motor and contacts. Unfortunately the operation failed and not in a great position either. It was neither in 4LO or 4HI, and we were still in Adelaide. The way these work is a long rod that has a rack and pinion that pushes a shaft in and out to engage high range or low range. My initial thought was open up electric motor assembly, either fix it or at worst push the rack into the correct position to get home.
This is from a different vehicle but it shows the core components of the actuator
The assembly is in a plastic housing. I foolishly thought what I was removing was just a plastic cover, however both sides hold components. So in removing the plastic cover, which required a bit of force to break the seal, many of the components fell on the ground.
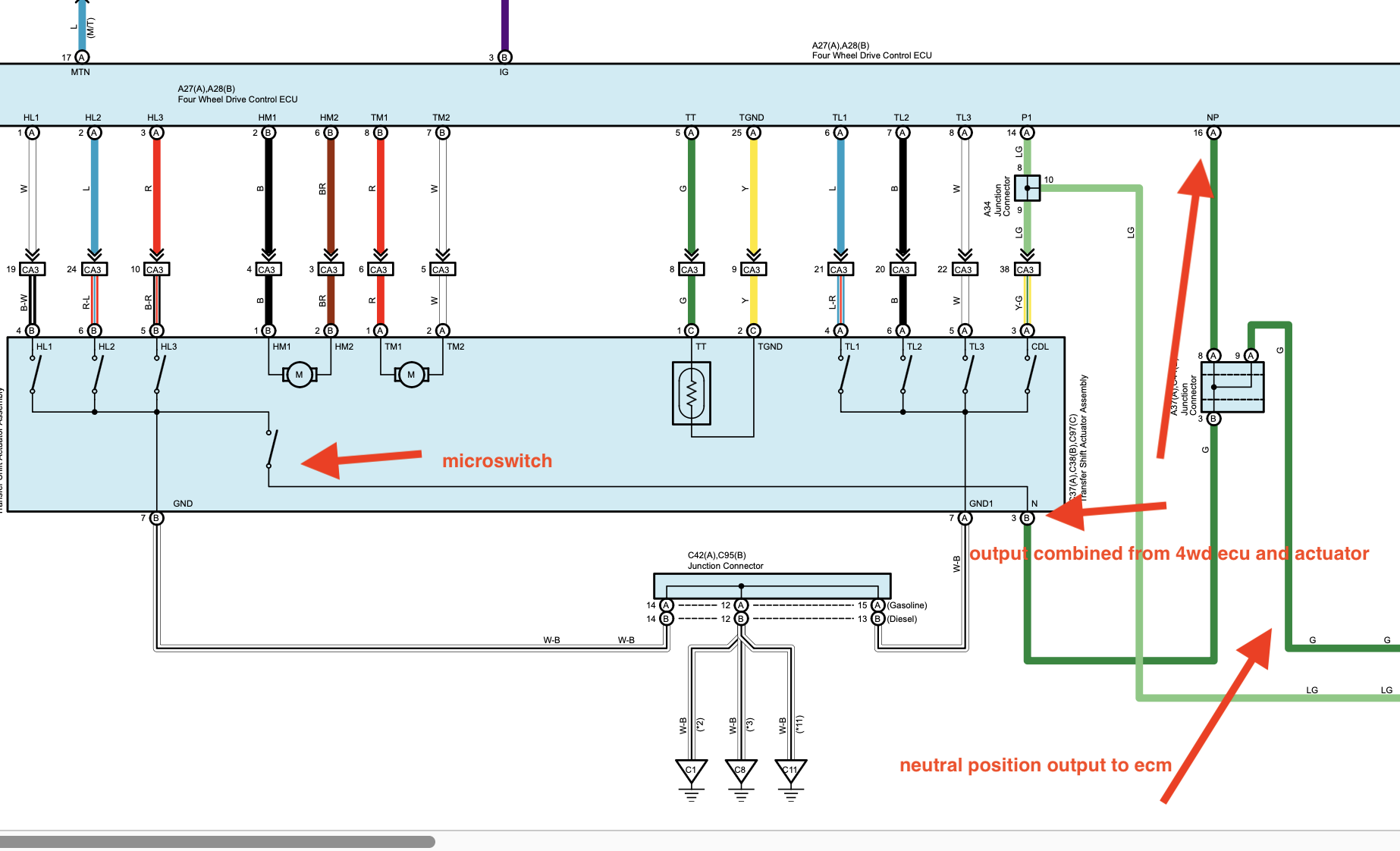
I’m not sure if I caused the microswitch to be damaged (I assume so) or if its been broken the entire time - but that seemed like a problem. Seems simple - just order a replacement micro switch - however that microswitch is unobtainable. It seemed to have only been made specifically for these transfer case actuators.
I forced the rack into the correct position and we drove home without issue.
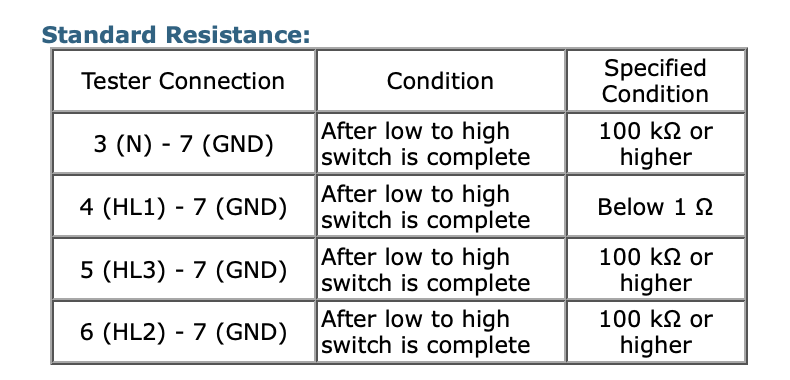
With no way to obtain a replacement micro switch (did consider 3d printing) and being unsure of the exact issue Droppy ordered a replacement actuator - $700. The actuators are known to get weak or not work correctly after time. This is a 2008 vehicle after all.
The “correct” way to perform this replacement is to drop the transmission and replace the entire actuator assembly (both center diff and 4lo). That’s not something we are going to do. The reason for this is that the actuators are “clocked” or aligned in factory so that the encoder slip ring contacts are lined up with the position of the rod. Removing the main gear removes this alignment which means it requires realigning/clocking/timing. IH8MUD (huge shout out, always a ton of good info there) has some advice on doing this alignment - but I’ll share a trivial method below.
When the new actuator arrived we instantly noticed that the microswitch for the 4LO system was missing. This actually wasn’t to unexpected - we were aware that new revisions of the part were missing the switch. The diff lock side still had the switch if we needed it.
The first step was to install the new 4LO actuator as is and see how it goes. The clicking remained and worse is that it didn’t put the rod into the correct position. It took about 6 to 3 minutes to change - and the slow transition resulted into some not nice noises (while it was getting in or out of gear). We initially thought that given that a DC motor was used that there was some calibration process that configured a motor powered timer. This was not the case.
Side note here. I was wondering why there’s “bad noises” when placing the car into park when the car is in between 4LO and 4HI. I think the reason here is because the output from the auto transmission has no resistance and is freely spinning as the wheels typically would force the shaft to stop. Putting the car into park will be resulting the parking pin trying to be inserted with the output shaft moving. If you know your not in 4LO or 4HI (neutral) then stop the car in neutral gear then shift to park.
When looking at the new and old part more carefully you can see why. The positions of the contacts are entirely in a different spots.
Droppy went and found a bunch of the part numbers and it seems like there are wide variety of parts with unknown compatibility between series.
Actuator
36410-60101 is 2017-11 -> 2010-01, but 36410-60102 can be substituted for that according to the parts list.
36410-60102 was fitted 2010-01 -> 2010-09.
36410-60120 (which we have) was fitted 2010-09 -> 2015-08
4wd computer:
89533-60240 (2007-09 -> 2007-11)
89533-60241 (2007-11 -> 2010-09)
89533-60380 (substitute for above) (2007-11 -> 2010-09)
89533-60242 (2010-09 -> 2012-01)
89533-60390 (substitute for above) (2010-09 -> 2012-01)
Transfer case:
36100-60B11 (2007-09 -> 2010-09)
36100-60B12 (2007-09 -> 2010-09)
36100-60B20 (2010-09 -> 2012-01)
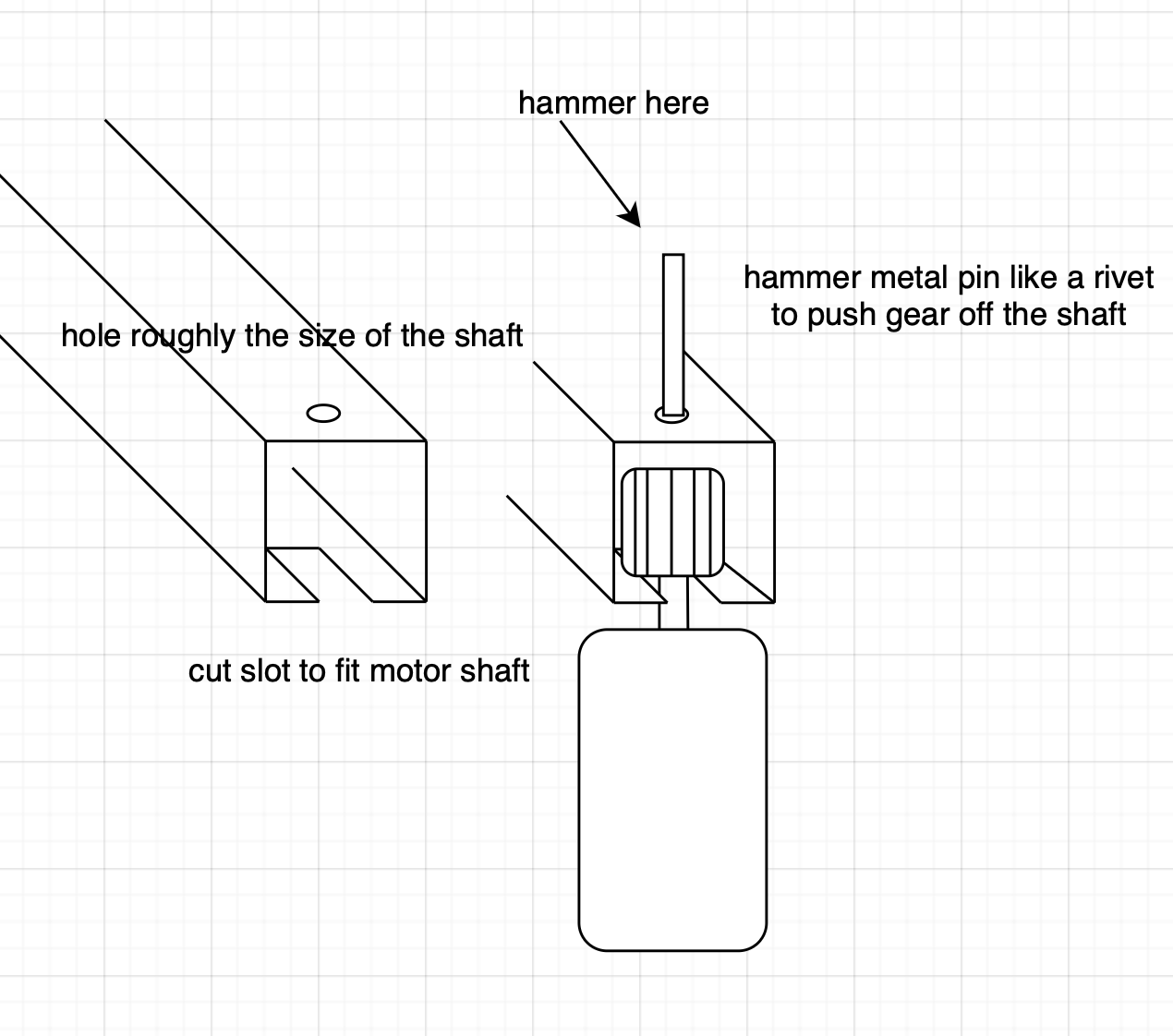
So the next idea - use the parts from the new actuator but the base of the old to rebuild one good one. Motor, gear, microswitch all replaced out. A gear puller was fashioned out of some box section (this was so I could use the center diff lock motor).
With the new/old one built it was reinstalled in the car and….. the same issue. Even running the assembly without the rack it still struggled to move around.
At this point all the wiring to the actuator was tested. All good and fine.
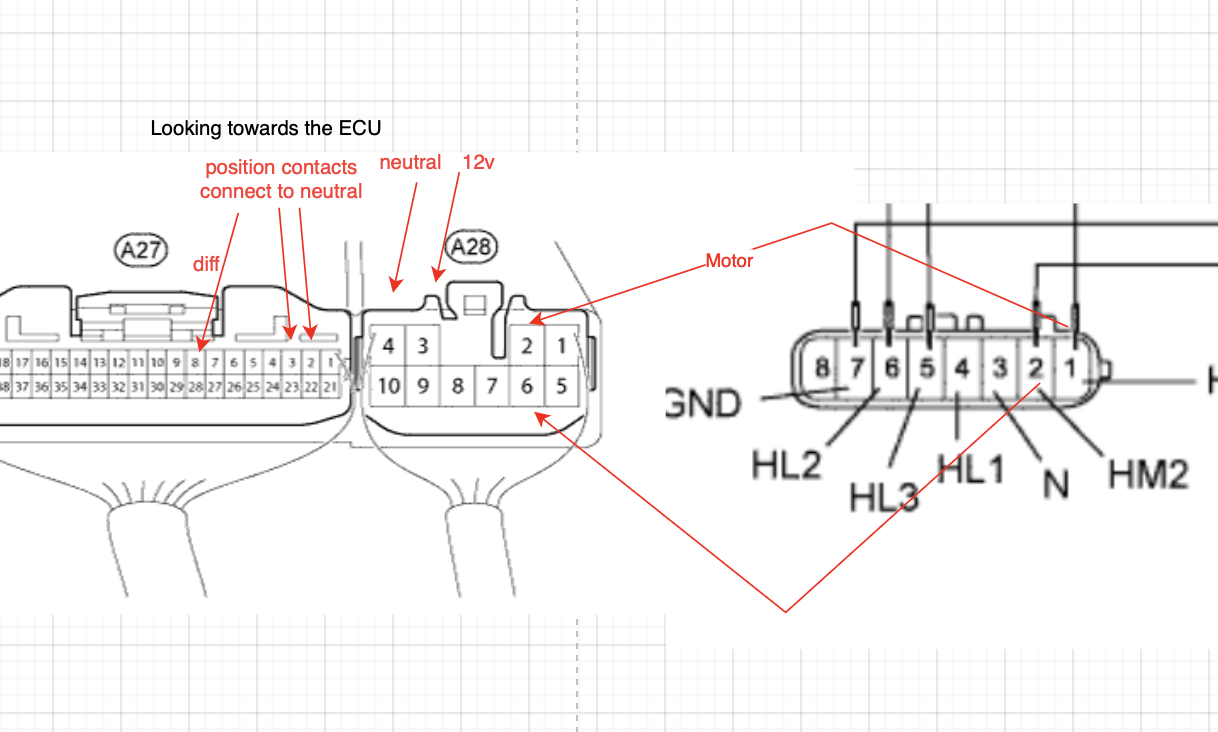
I guess the 4WD ECU is dead? Alex helped me remove the drivers side dash and panels to get to the 4WD ECU.
Removing the case from the 4WD ECU, nothing revealed itself.
Although the 4WD ECU has CANBUS maybe it’ll still set the actuator position at start. After running through the wiring for the actuator and 4WD ECU a ton of times we were able to trigger it to run the actuator on the test bench and …. it works. So what the heck is going on in the car.
The 4WD ECU can (well ours can) be tested on the bench by faking some signals. We can use the service docs to find those signals.
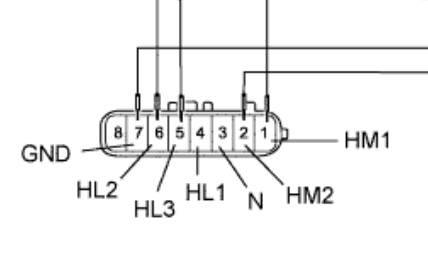
The motor is connected to pins 2 and 6 on the large pins of the ECU. These correspond to pins 1 and 2 on the actuator side. You can connect these either way during testing if you aren’t placing the gear assembly in the housing as the motor will just spin the opposite way.
Pins 1,2,3 on the small pins correspond to the position sensing of the 4HI/4LO actuator. These are either disconnected or connected to neutral to signal position. From memory I connected pins 2 and 3 to neutral to trigger the motor to spin. This should signal to the ECU that the transfer case is in between 4LO and 4HI
For power of the ECU, pin 4 on the big contacts is neutral and pin 3 for power.
I also connected pin 8 on the small contacts to ground to simulate the diff being in the correct position.
To make the connections I used alligator clips on the large pins alternating between using the pins or making connections on the back of the connector. For the small pins DuPont connectors were used.
Please don’t trust me, double check my work.
Thinking some fucky electrical thing was happening we disconnected all the dual battery system, removed all the electronics that were plugged in and removed all the main body fuses that weren’t necessary. This did not help.
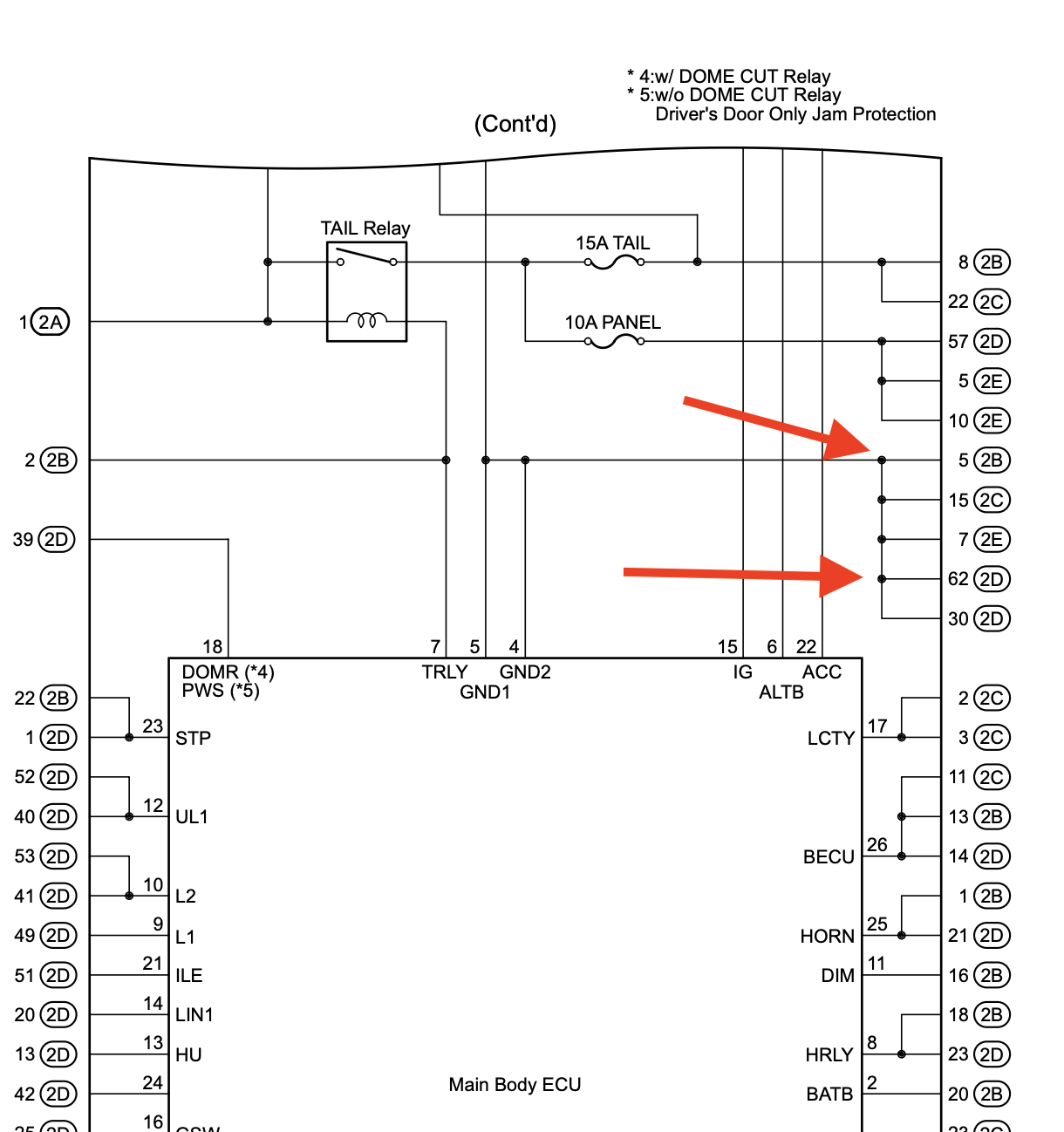
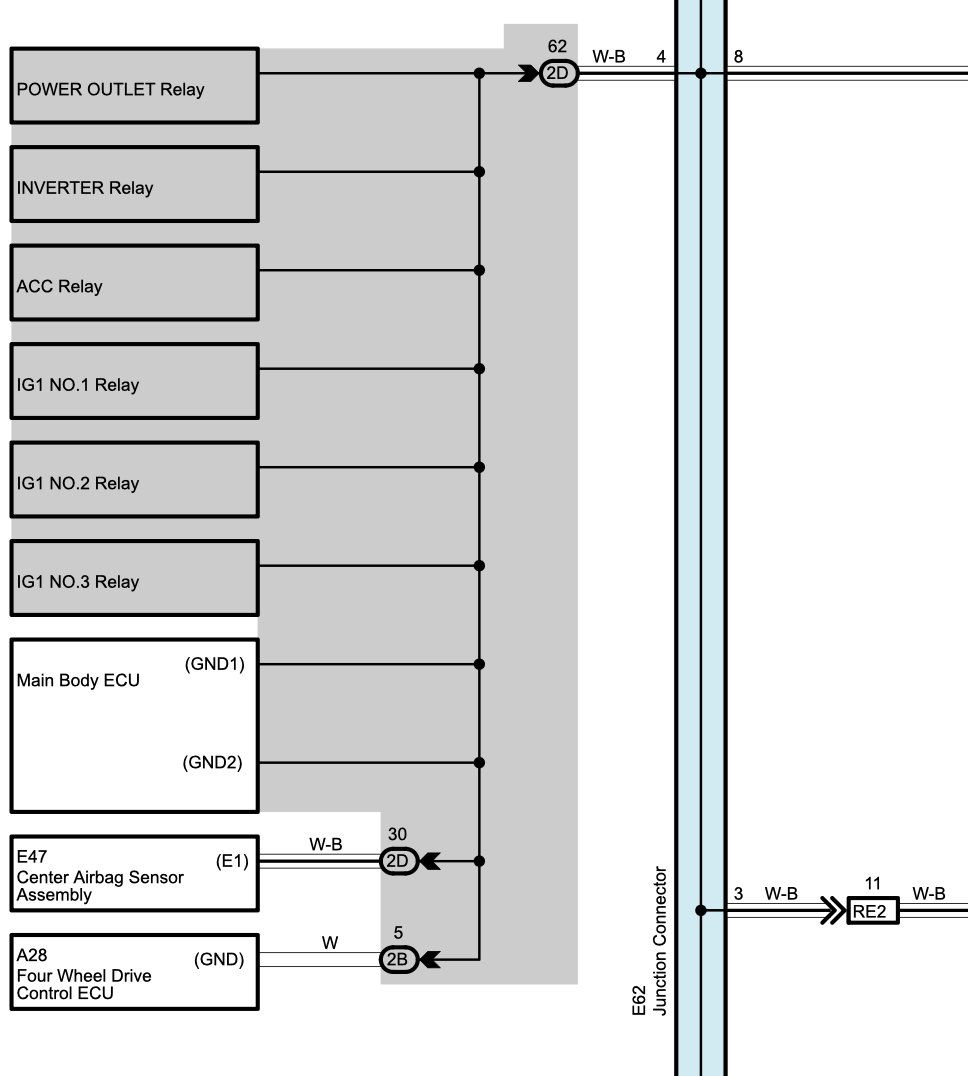
The next part was to test the wiring to the 4WD ECU itself. We noticed a ~5 Ohm resistance between the 4WD ECU neutral terminal and the body of the car - which seemed a little high. This indicates a wiring harness fault. Uh that’s not fun.
I expected that the neutral would be found near the drivers dash as well - however the neutral runs all the way back to the Main Body ECU in the passenger side dash. Sigh. Ok all the passenger dash ripped out to get to the Main Body ECU.
I spent far too long trying to work out how to remove the Main Body ECU however once the glove box is removed it does just come straight forward. We had a lot of extra cables in the way that made that non obvious.
With the ECU removed we tested the resistance between the two ends of the wiring harness - fine. We tested the neutral between the Main Body ECU and body earth - fine. What the heck is happening. Then I decided to test the neutral across the front and back of the ECU. 350 Ohms.
That’s uh. weird. We removed the cover from the ECU and found the secret “fuse”. For some bizarre reason Toyota thought it was completely ok to run the neutral for bunch of subsystems across this tiny trace which wouldn’t be able to handle the max fault current in the slightest.
At least the fault was self evident though a clean break would have made troubleshooting easier. Some bodge wire was added. The actuator motor now spins fine.
So how did this happen. Well remember at the start when I said I was messing around with doors. I believe while I was metering out what to cut I caused a short. I didn’t think much of it at the time because no fuses blew and everything worked ok. Now that that the Main Body ECU PCB trace is fixed the doors work fine.
I did wonder if maybe there was a lifted neutral as well. But checking the circuit diagram reveals that everything I’ve discovered is the correct/only neutral path.
What was left to do was align the actuator position/timing (“clocking”). I discovered a fairly novel way of doing this. Hold the assembly in your hand, connect it to the car, but don’t connect it mechanically. Hold it in a way that your hands are clear from the gears (it moves faster than I thought it would), but applying a bit of force to the shaft to keep the contacts down - then have someone turn the car to on (don’t need to crank) and let the motor spin and it should stop at the correct position. For us, setting the 4WD to 4HI is easiest as the then rack just needs to be pushed ALL the way in. Without adjusting the position of the actuator gear, now insert it into the rack and screw it down. It should be in the correct position.
Now about that micro switch - it’s not required. I suspect the purpose of this switch was to signal to the car/transmission that the car was effectively in neutral. I believe it might throw an A/T/P warning (warning you that the transmission isn’t in park so the car can roll away if the parking brake isn’t engaged) when this switch is active. I guess maybe Toyota were concerned that the 4WD ECU might fail and not report the neutral position, or possibly that part might be replaced with one that doesn’t output the signal?
However the transfer case already knows this information (it’s how it knows to keep driving the motor) so they likely just removed this from future versions since the switch was pretty useless and kept breaking. I tested that the switch isn’t needed by taking the left over no micro switch version and letting it run from 4HI to 4LO without issue.
Here’s a video of the actuator being clocked and the microswitch not being required.
Amateur Radio Experimenters Group (AREG) decided to plan a winter balloon launch. Something that they typically don’t do due to the unpredictable weather and cloud cover.
One of the ideas for the winter launch was to be a crossband FM repeater and the increased winds to Victoria would mean a larger coverage area for possible interstate communication. The other (and more interesting to me) benefit was real world testing of the webhorus and webwenet sites which simplifies decoding of both balloon protocols. While others had used the app and reported success, I had only ever tested it in my lab. It’s a bit of a weird experience to have never used my own application in a production setting.
The first possible launch date got pushed back due to bad weather. The second launch window wasn’t looking much better and if that was cancelled it was unlikely that the launch would go ahead until much later in the year.
The predictions were showing a longer distance than we could travel (legally) during the flight time - meaning that we likely wouldn’t be near the landing site on touch down. Chance of recovery would be lower.
Keen to still test my software I ask Mark if we I provided a small low cost payload if we could fly something.
I rushed together parts I had for a Wenet transmitter. Given the main payloads weren’t flying maybe I should try something a bit more experimental in nature.
As AREG is in Adelaide and I’m in Melbourne it also meant driving the 8ish hours across. It was agreed that I would build up the Pi / transmitter and the box, antenna and camera would be installed when I arrived - leaving only a few hours in the evening for that integration to happen before launch the next day.
I2S PCM Audio
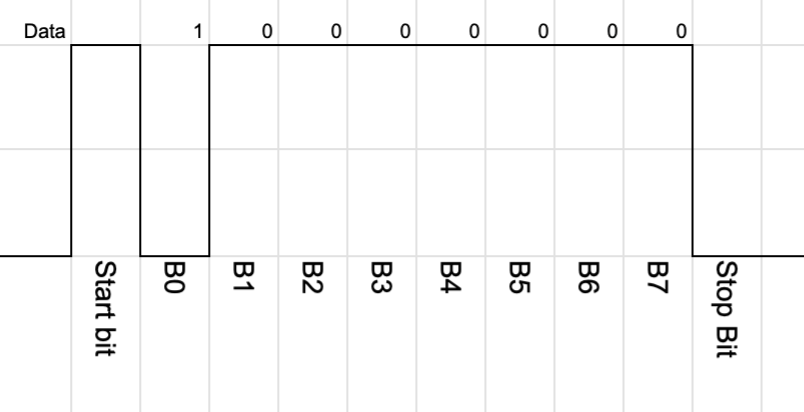
While developing webwenet I learnt a lot more about how Wenet worked. One thing that really stood out was that Wenet receivers need to remove RS232 framing from the data before decoding the packets. This initially struck me as odd. What does RS232 have to do with this protocol.
Today most Wenet transmitters use a RFM98W, usually on some LoRa shield/package. The UART pin from the Raspberry Pi is connected to DIO2. The chip is configured for a 2-FSK direct mode, bypassing pretty much all the smarts of the chip itself. If the DIO2 pin is high it transmits one tone, and if it is low it transmits the other.
Since the UART is used to transmit the packet that means that RS232 framing is also transmitted.
I had a quick look at the Raspberry Pi datasheet for the UART and didn’t really see a obvisous way of disabling the start and stop bits. It would be possible to bit bang data out - but timing is important for us on RF so I didn’t explore this option.
The Raspberry Pi however has a ton of different interfaces. Maybe another one would work better without the framing. My first thought was - maybe we could just bit bang a GPIO. The Pi is pretty fast and we can use some kernel features to make that work.
My next thought was along the lines of SPI, but Droppy reminded me that the Pi has I2S output - which is IMHO the classic bit banging target.
Well before the Horus flight was even planned I prototyped an I2S version which emulated the the UART (basically adding back in the RS232 framing) to compare in the lab.
Now the proper way to implement this is probably to access the I2S interface directly, however easiest approach for me to use the RaspberryPi_I2S_Master device tree driver which adds a generic sound device. This is expected to be tied to a audio chip - but we just ignore that part. From the code point of view we import alsaaudio and generate the correct audio frames.
Some complications show up though. The linux simple-audio-card driver seems to have fixed set of sample rates and channels. I don’t think there’s a specific reason this needs to be the case, but without building a new kernel module it means a little bit of extra work. Now channel wise it doesn’t matter so much, we send the samples irrespective of which channel is selected (that pin gets ignored entirely) - but we do have to factor the channels into our data rate.
So with only hand full of sample rates to choose from how do we get the bit rate we desire. At startup we calculate the desired RF bitrate and then work out multiples of the audio sample rates.
For example - if the audio sample rate is 48000, the number of channels is 2, 16 bit audio width and the desired RF baud rate is 96000, then the audio bit rate is 1536000, then we divide by 8 bits per byte - 1536000/8 = 2 bytes. So for every “1” bit we send two bytes - 0xffff and for every “0” bit we send 0x0000.
In testing however I noticed that my transmitter just wouldn’t work when running the software. It turns out the Wenet TX software had an LED configured for the same GPIO that was used for I2S PCM out on the Pi. Annoyingly when this GPIO is set the Pi had to be rebooted before the I2S output would work again!
To make use of the advantages of I2S approach I needed to write new transmitter code which didn’t include the RS232 framing, update the existing Wenet receiver software, and my webwenet code. This was a big undergoing so close to the flight deadline, but we managed to do it.
By removing the RS232 framing we remove the 20% overhead from start and stop bits. This allowed us to pick a lower RF bandwidth while still being slightly faster than the original system.
Modulation testing
It’s all fine doing this in practice and testing locally where SNR is high, but we need to make sure that both the modulator and demodulator is working correctly. Subtle errors in things like the parity code, timing mistakes or off by one errors won’t be apparent until low SNR.
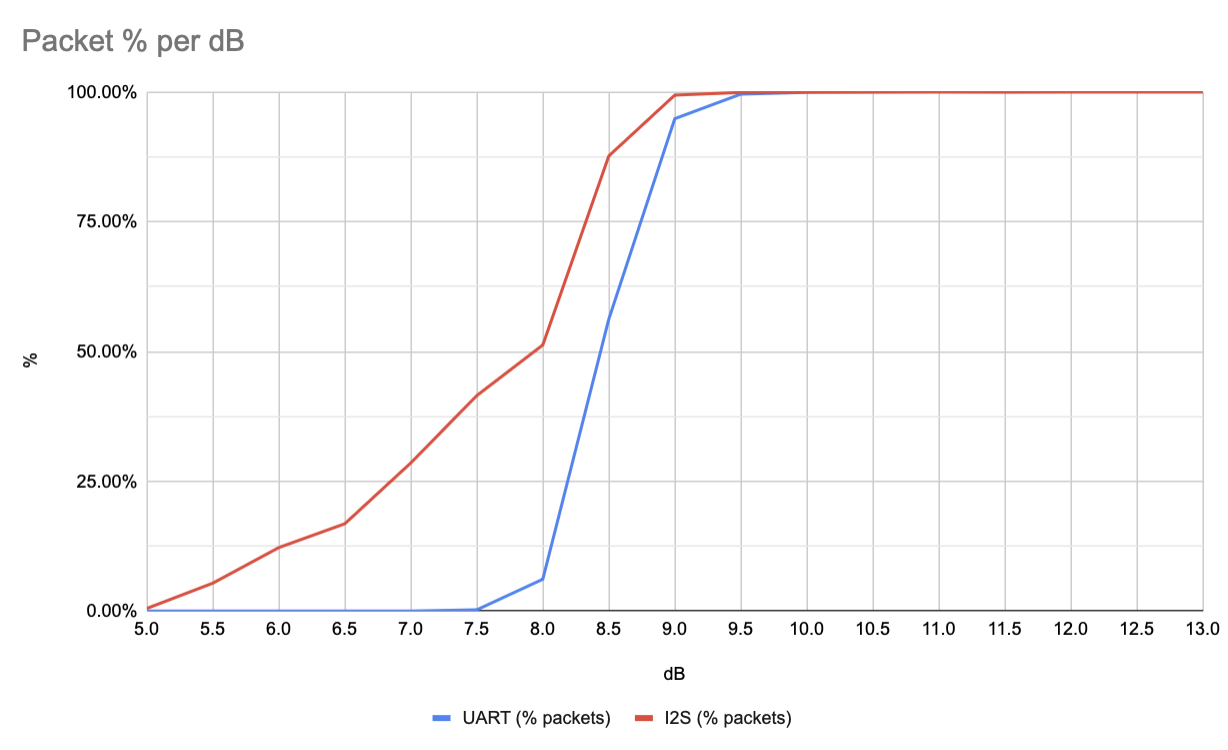
To do this Mark built some benchmarking scripts. These take a high SNR recording, then generate lower SNR samples. The lower SNR samples are feed back into the demodulator and a count of the packets decoded is taken. With the low density parity check (LDPC) and the quality of the modem we expect a fairly sharp fall off. The nice thing about these scripts is that they normalise for Eb/N0 (SNR per bit). This means that even though our baud rate is different we can still compare the new I2S method to the old UART method.
When we run this I2S we see similar dB threshold where all the packets are received however there’s a bit of a weird slope. We expect that due to the parity check that either you receive a packet or don’t, so the dB difference between that threshold point should be small. This lead us to believe that the testing wasn’t working right.
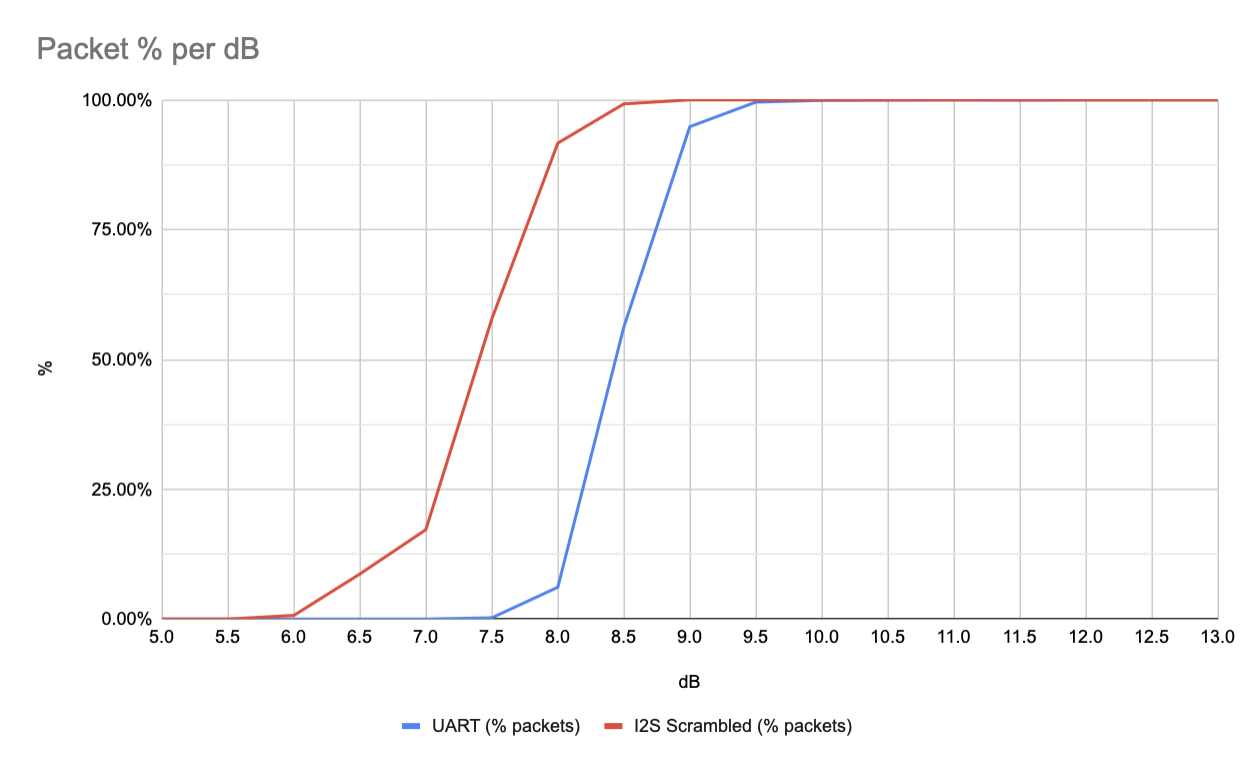
Now one thing that we noted when switching to I2S is that the UART method didn’t include any sort of scrambling or whitening. Scrambling is used to ensure that there isn’t a long run of zeroes or ones which could cause the modem to loose timing and become unsynchronised. For the UART mode this wasn’t a big concern because the RS232 framing meant that the start and stop bits would always cause a 1 and 0. Switching naively to I2S meant that we lost this free bit flip.
The theory I have at the moment is that the long runs of 1s or 0s in the I2S approach breaks the normalisation scripts. Adding in scrambling we get a much sharper cut off as expected.
Dual mode
While I was pretty confident in the I2S approach we wanted to be able to compare the two modes in a real world setting. A normal person might just fly two payloads or have two transmitters. Instead however I decided that it was likely possible to have the software switch between the two modes.
To do this a soldered diodes to the output pins on the Pi and feed both UART and I2S to the RFM98W module. With the hardware done, we need to look at the software. The first problem is that the UART transmitter needs to disable its output when its not active. To do this we use the break_condition attribute in pySerial. I2S luckily sits low normally so nothing needed to be done there. Finally we need to switch between the two modes in the transmitting software - which it was never really built for. I hacked in the functionality to have a list of radio modules which are cycled only when the radio is in an idle state after a period of time.
The result was that the radio switched between modes roughly every 1-2 pictures.
Testing deadlines
I moved my code over to the target Pi Zero 2 W. Went to plug in my PiCam only to find the connector is different between the Zero and the normal Pi. From a “launching the balloon” point of view it wasn’t going to be a problem as the camera was being supplied by Mark however from a testing point of view it meant I wasn’t going to be able to test that the camera functions. I rushed off an order to Amazon for a camera module that did have the correct cable.
In the meantime I tested without the camera module. I had some extremely weird issues. File descriptors were being opened and after about an hour the software would crash due to reaching the ulimit. Debugging the issue and I couldn’t determine what was causing it - I thought it was caused by swapping between the two radio modes, but that didn’t seem to be the case.
I tried a bunch of Python debugging tools to see the cause but couldn’t nail it down to any Python code. It seemed to be occurring due to the picamera2 Python module. It seems that file descriptors were being leaked due to the lack of camera connected - but I wasn’t entirely certain. To alleviate the problem I bumped up the max number of files open in ulimits however it turns out that select is limited to 1024 file descriptors anyway - so that option didn’t work.
I quickly added a shell script to check for open file descriptor count and put into the watchdog.d config. If it got too many fds it would reboot and everything would be fine. It’ll do.
Integration woes
Arriving in Adelaide I passed the payload to Mark who quickly fitted it into the box, added the camera and we fired it up.
Two issues presented us. The GPS didn’t stay locked / struggled to lock. I had seen some of these issues with my testing - we’re not entirely sure why my uBlox 6 chip wasn’t working correctly as ubxtool showed correct data. Current suspicion is that the code was written for uBlox 7 and isn’t happy with some of the data. The other factor is that I was using soft serial (as UART was taken for I2S transmitter). After some quick debugging we opt’d for replacing it with a known good USB GPS module.
More concerning was that with the new camera connected the Pi rebooted shortly after initial boot up. We believe this was a kernel panic but with no swap setup to do coredumps we don’t really have any logs of that. I believe this was to do with the PiCamera 3 module as I didn’t see the reboot happen in my testing.
The reboot didn’t happen often and the system started up again just fine. But it’s not something I really like to see before launch. The picamera2 github is full of issues of people having random issues with the library. I even saw some issues where Python crashed somewhere that it practically couldn’t, and I think this was also caused from the picamera2 library - my guess is that it lacks thread safety and incorrect/lack of locking.
I put in some extra error handling. We did a few tests and it seemed fairly stable, even if it did reboot. However it exposed a known limitation in webwenet. Wenet protocol sends images with a byte for image header, followed by a byte for an image id. Restarting the payload resets the image id. When webwenet receives an image is combines all the packets for an image based on the image id. With the image id reseting the images were being updated rather than replaced in the UI. So a last minute patch/hack was added so that users wouldn’t get confused if the image id was reset.
Launch day
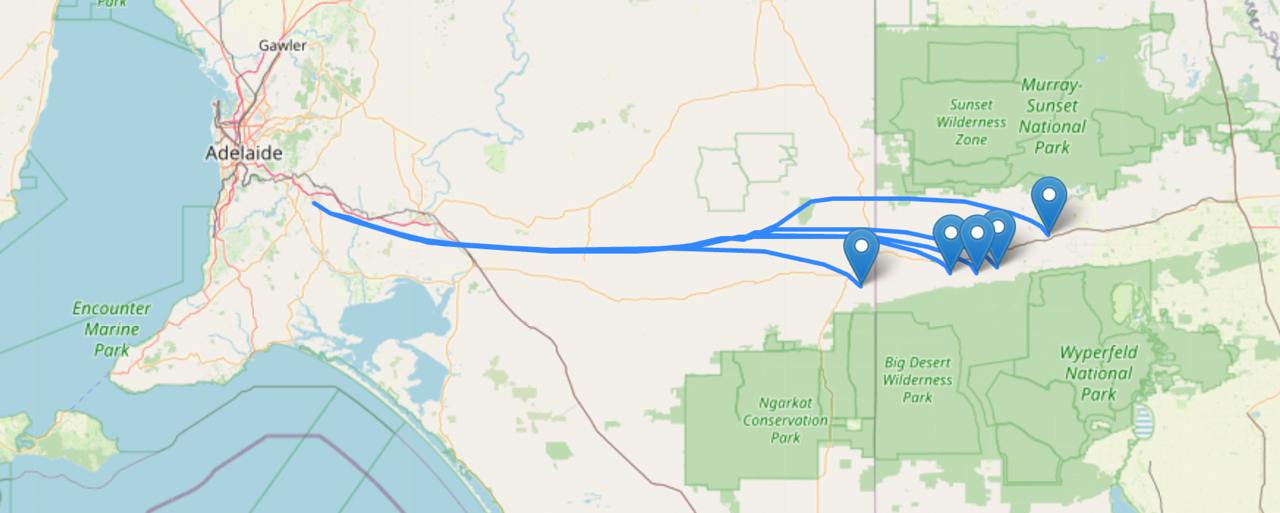
We arrived at the launch site. The car was prepped for receive mode and the balloon was filled. Up until now we hadn’t really decided if we wanted to chase the balloon, or if we wanted to get to a higher location to have a better chance of receiving as much data as possible. We opt’d for the high location and would attempt recovery on our drive home the following day.
Many hands were required to handle the balloon during filling and tying off, but eventually it was filled and launched.
Droppy drove while Alex and I monitored the balloon and receivers. One of the things I wanted to test with webwenet was around lowering the entry requirements for receiving. What would be the minimal equipment needed to receive?
The LNA4ALL was chosen as it can be powered directly from the RTL-SDR using the Bias-T option. The LNA4ALL does need a small modification to allow this.
I created a few little brackets for our cars roof rack that mounted the LNA close to the antenna.
The small vertical antenna is used while driving as it provides low gain. A higher gain antenna would result it a more narrow beam which isn’t very useful if the balloon is high up.
Once we arrived at the high location we switched to the yagi antenna which provided a reasonably good SNR throughout the rest of the flight.
This setup worked fairly well and was pretty on par with some of the bigger setups we saw on the day.
Fun with phones
One of the fun things with webwenet and webhorus is that you can load it up on mobile phone browsers. This meant that we hooked up a mobile phone on a many-element yagi - something that just seems extremely ridiculous.
Pi Camera 3 Focus issues
As images started streaming in it was obvious that a long running issue with the Pi Camera 3 had struck us. Out of focus images. Current suspicion is that the payload is moving too much for the Pi Camera 3 to obtain proper focus. Which is a shame because some of these pictures would have been stunning. Regardless I still think they look pretty good.
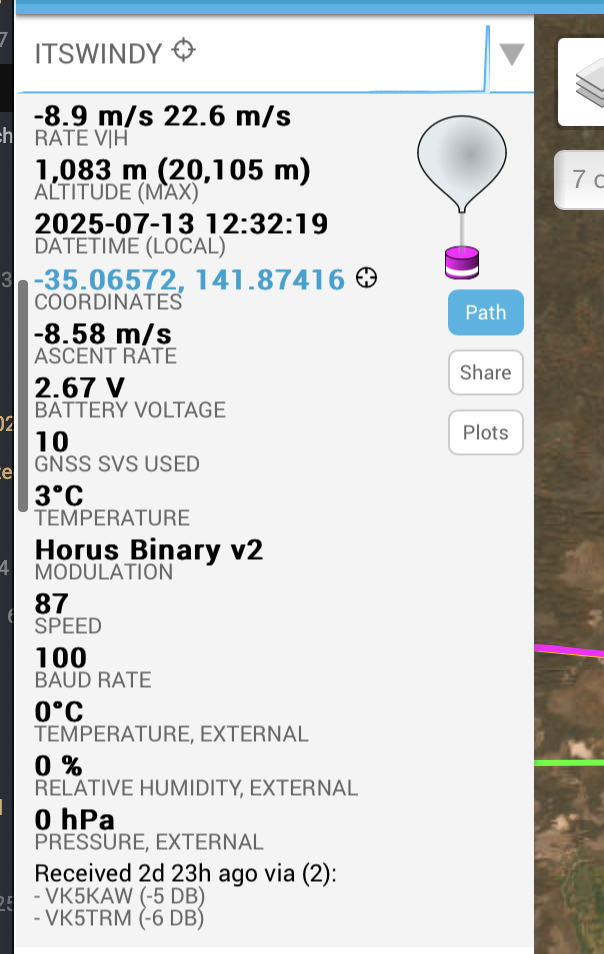
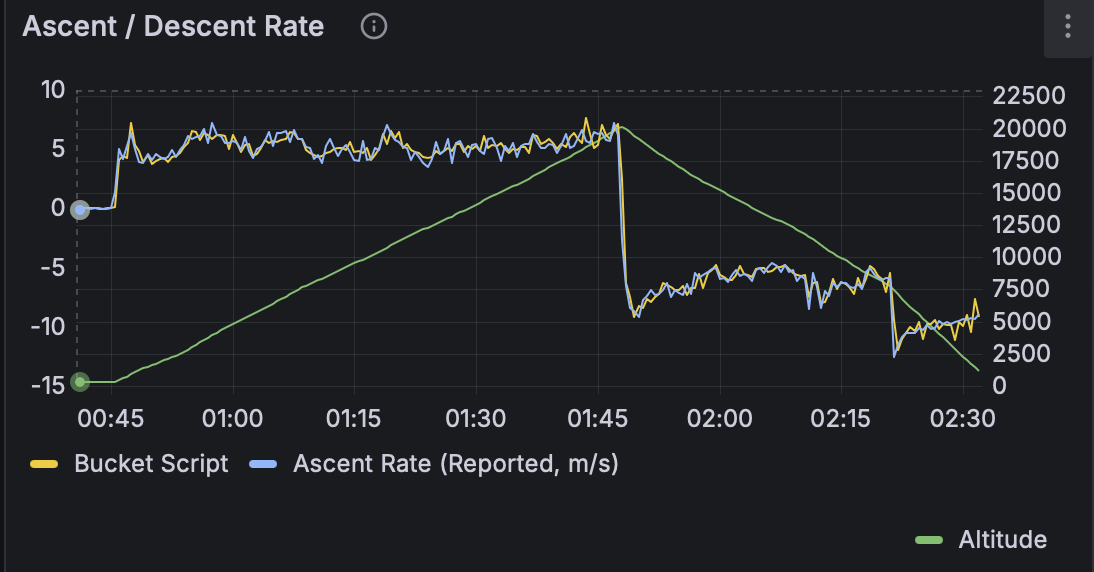
The highest picture was recorded at 20,116m.
Landing and recovery
The balloon landed over 250km away. The last reported altitude was 1,083m.
. During the descent we noticed a rapid change in descent rate. This was an indication that the parachute had failed. The parachute was bright red and was going to be necessary to find the payloads.
Being so high up for the last reported location leads to a very large search area. Local ground winds play a huge part in final landing location, so it was going to be a challenge to recover. Probably unlikely given that the transmitters batteries would now be flat and uncertainty regarding if the balloon still had a red parachute to spot.
Arriving at the predicted landing spot, the farmland covered the repeating dunes. Luckily being winter the fields were bare. We stopped on the second dune near our suspected landing location and walked across to the next. Not even sure which field it had landed in we kept scouting around. Part way up the next dune I spotted in the distance a red patch with two white items near it. It was a long way away but given it was unlikely that the field would otherwise have something like that in the middle of it I was pretty certain that it was the payload.
Walking across the field I arrived at the landing site. It was a surprise to recover the payloads with the data we had, let alone find them so easily. I guess one advantage to winter launches is empty fields. Enjoy the time lapse created from the remaining battery on the image transmitter payload.
After bringing the payload back we opened it up and turned it back on to get a group photo before heading back home.
The final verdict on I2S
It performed no worse than the UART version. The theoretical performance increase of the lower RF bandwidth requirement isn’t actually much - to the point that it’s in the testing noise. We do know that the data rate is slightly faster though. The other advantage is that it frees up the Raspberry Pi hardware UART for other tasks. It sounds like AREG will be flying I2S Wenet going forward after the success of the dual mode payload.
Thanks
Many thanks to AREG, Mark, Droppy, Alex and all the receivers who let me fly this payload, help with recovery and put up with my bullshit.