Do you want a search engine that works like old Google? Distributed and run by the people? Free and open source? No ads or tracking? Mastodon for search engines????
I’m going to introduce to YaCy, which is exactly that. Then break your heart and tell you why it doesn’t work.
YaCy is a distributed search engine and crawler which uses similar tech to torrents (distributed hash tables). It allows for anyone to start crawling websites and running a search frontend. The peer to peer nature of it means that while your node might not have crawled a specific site or information, another node might have - allowing for searches to be distributed across the network and hopefully returning a result for your query.
Some time ago I wondered, on modern internet connections and todays cheap storage, how hard could it be to run your own search engine. YaCy popped up in my searches and I thought I would give it a go. Estimates for Google’s index size vary from 30 billion to 400 billion. That might seem like big numbers but for computers these a tiny. Also to make things easier we can limit ourselves to purely text documents and if we avoid indexing useless or low value websites we can bring that number right down. My finger in the air estimate is that a search engine with 3 billion indexed high quality pages is going to be just as useful for most people.
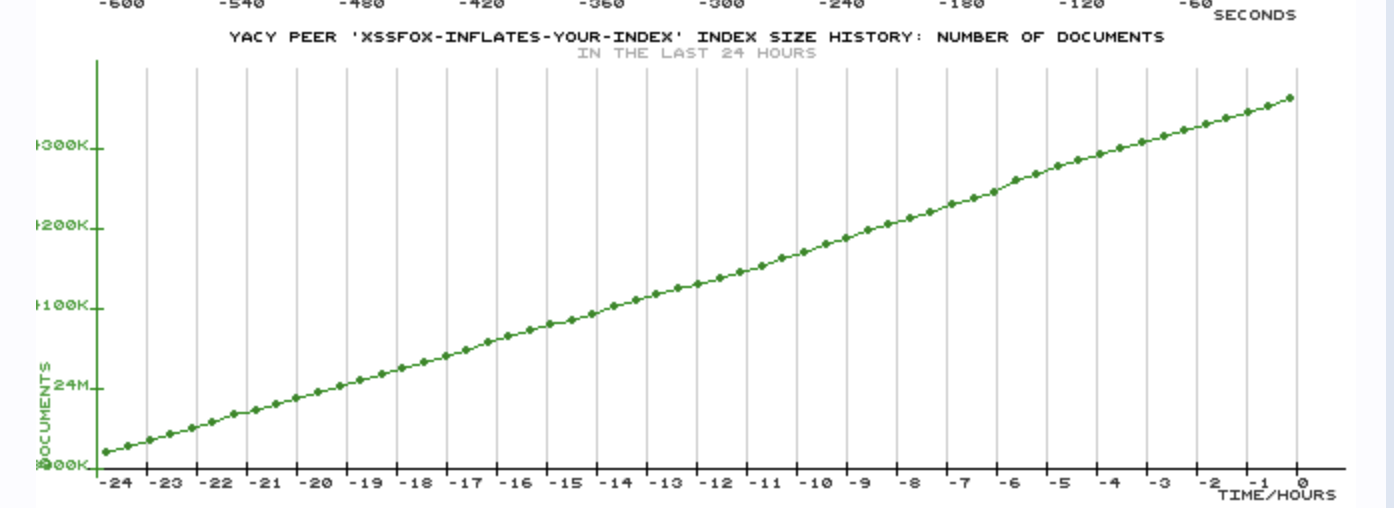
With that in mind I bought a beefy box from OVH, configured YaCy and set it crawling the web. In less than a month its indexed 24 million pages.
while the entire YaCy network has around 2.4 billion indexed documents. My node can easily index 1000 documents a minute if given the chance. One of the neat things about YaCy is the concept that a website can run their own node to provide search results for their site search and any other remote queries on the network. For example Wikipedia could run their own official Wikipedia YaCy instance.
It all falls apart when you try to use it however.
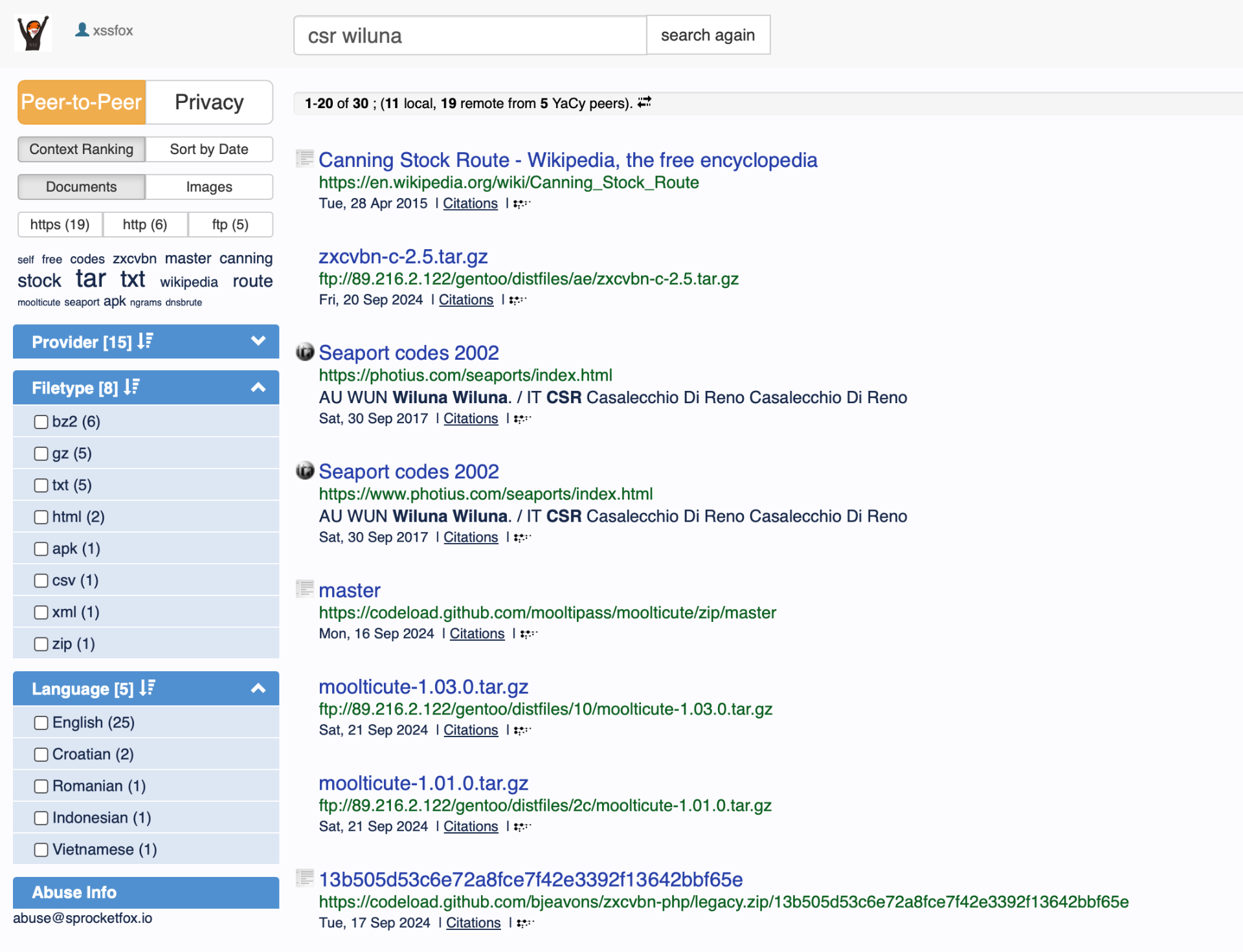
Search results are often lacking useful content and more often than not unofficial/low quality pages will rank higher than official or trusted sites. Often I just random ftp servers, tar balls and zips. Now there’s probably some settings I can tweak to make site ranking a bit better - but it’s not a good start.
Slight tangent here. While playing around with YaCy I also found SearXNG. It’s an opensource metasearch engine. You configure multiple search backends and when you search it performs that search across all of them. So you can get Google, Bing, YaCy, DDG all in one. If using YaCy I suggest setting this up. I’d love to have the results from other search engines then get fed back into YaCy to index.
This brings me towards why YaCy isn’t really usable today (or probably ever). Google Search from yesteryear just wouldn’t work today. A lot of content is behind walled gardens - such as Facebook and X. But ignoring these areas modern webpages are JavaScript heavy - often empty pages that are loaded through API requests.
I hear you screaming “what about SEO?!?”. Apart from SEO being silly, it’s now GEO, Google Engine Optimisation. Displaying or rendering content specifically for Google. If you attempt to scrape websites using the YaCy user agent you are often left with disappointment. If you think you can just switch to a Googlebot user agent your left with being blocked by WAFs and CloudFlare for not coming from the right IP / AS number or other types of fingerprinting. Places like StackOverflow try very hard to not have their content scrapped as it would destroy their business model.
Today we have a new problem, AI scraping. YaCy practically appears no different to an AI scrapper when using a Googlebot user agent. The AI scraping shitstorm has effectively stopped another search engine crawler from existing.
Regardless of the crawling issues, the way we use search engines, and the quality they provide has also shifted. YaCy’s basic search algorithm just isn’t suitable. The key component to this is having the search engine understand not just the word but the context of the word. For example “monitor” could mean a computer monitor, or to watch something. The search engine should use the other words in the query to determine which pages relate to the type of monitor. This is especially important given the rise of keyword stuffing and AI generated slop.
Side note about AI slop. One of the things I have found surprising is that YaCy has very rarely given me results for AI slop. I’m not sure if this is because AI slop is less indexed, or the SEO optimisation that AI slop performs isn’t effective with YaCy, but it is an interesting observation.
We also expect additional features, for example I often search for “time in $x” and “weather” to get quick previews. Maybe for these I should move to tools outside a search engine.
YaCy itself is dated. It’s a fairly old project and development has slowed down. Slow development itself isn’t a problem but it’s design and architecture leaves a lot of be desired. I get the vibe that there’s probably some security issues hidden in the old code base waiting to be discovered. The other part is that I don’t think there’s been enough attention to privacy and moderation. The controls they have today kind of work, but it’s not something I’d suggest using if you want your queries to be kept private. It’s very easy for crappy spam to end up indexes as well.
My other concern is that if everyone was to rush out and install this software, we’d have a ton of people scraping popular (or even non popular) websites like Wikipedia unnecessarily. How to balance freedom and coordination here is a little tricky.
That doesn’t mean YaCy is all bad. It can run in several modes - the one I’ve been talking about is the “community based web search”. While I haven’t tested it out yet, there is also “Intranet indexing” which you may find useful for indexing your local file server.
YaCy remains a project I want to succeed and work well. The dream and concept is great. Reality unfortunately places it in the not very useful category.